Abstract
Continual learning (CL) aims to learn a sequence of tasks without forgetting prior knowledge, but gradient updates for a new task often overwrite previously learned weights, causing catastrophic forgetting. PAH (Prototype-Augmented Hypernetworks) solves this by using a hypernetwork that generates task-specific classifier heads conditioned on learnable task prototypes. It combines cross-entropy with dual distillation losses for stable learning and achieves state-of-the-art results on benchmarks like Split-CIFAR100 and TinyImageNet, without relying on rehearsal buffers.
How It Works
PAH uses a single hypernetwork shared across all tasks. This hypernetwork takes as input a learnable prototype that represents a given task and outputs the weights for a task-specific classifier. During training, both the prototype and the shared feature extractor are updated. During inference, only the current task prototype is needed to generate the classifier head.
Why It Works
Prototypes serve as compact, semantically meaningful representations of tasks, initialized using actual training data and optimized to remain aligned with the evolving feature space. This alignment ensures that the hypernetwork can always produce accurate classifier heads, even without explicit task identity or replay memory.
Model Architecture
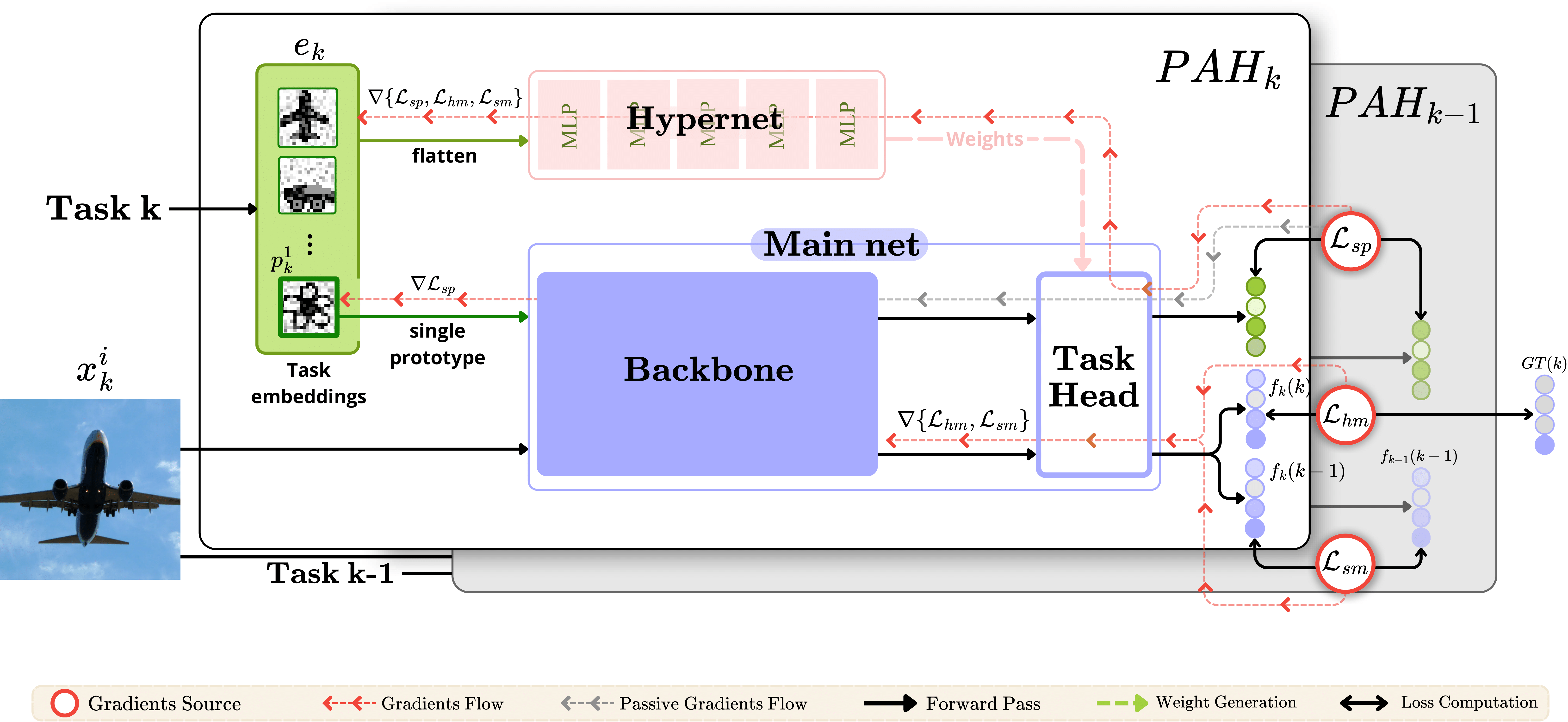
Learnable Task Prototypes
Each task has a prototype grid (e.g., 10×10) formed by stacking class-level feature maps. These grids are flattened and fed into the hypernetwork to generate the classification head. They are optimized using a KL-divergence loss to preserve semantic alignment over time.
Benchmark Comparison
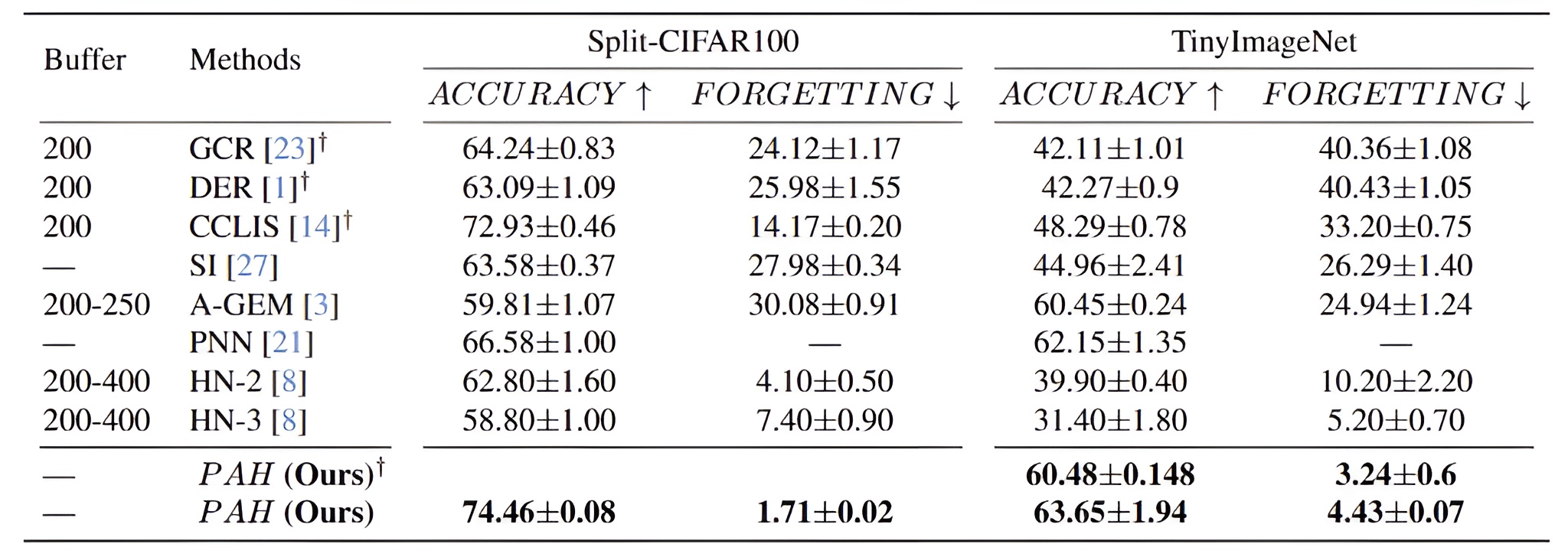
The Table above compares PAH with state-of-the-art baselines on Split-CIFAR100 and TinyImageNet. PAH consistently outperforms competing methods, achieving low forgetting and robust accuracy across tasks. On Split-CIFAR100, PAH attains 74.46% accuracy with only 1.71% forgetting, surpassing methods like A-GEM and SI. PAH also outperforms CCLIS, which has similar accuracy but substantially higher forgetting. On TinyImageNet, PAH achieves 63.65% accuracy and 4.43% forgetting, outshining replay-based and hypernetwork-based methods like GCR, DER, HN-2, and HN-3.
Reproducibility
You can check our GitHub repository for instructions on how to execute and reproduce all experiments in the paper and find information on how to download the datasets there.
Poster
You can view and download our poster below or from this link.


 2
2 3
3